

Are you wondering about the buzz around Generative AI? One fact is clear: Generative AI is quickly reshaping the world around us i many different ways.
Generative AI models like GPT-4, Mistral, Gemini, LLaMA, and Claude exhibit remarkable versatility in generating text, images, and code. These models find applications across a broad spectrum of industries such as content creation, chatbots, coding assistance, finance, healthcare, technology, graphic design and education and most of us have tried them in some form or the other.
This guide will unfold how these amazing models work and solve complex problems.
An Overview of Generative AI Models
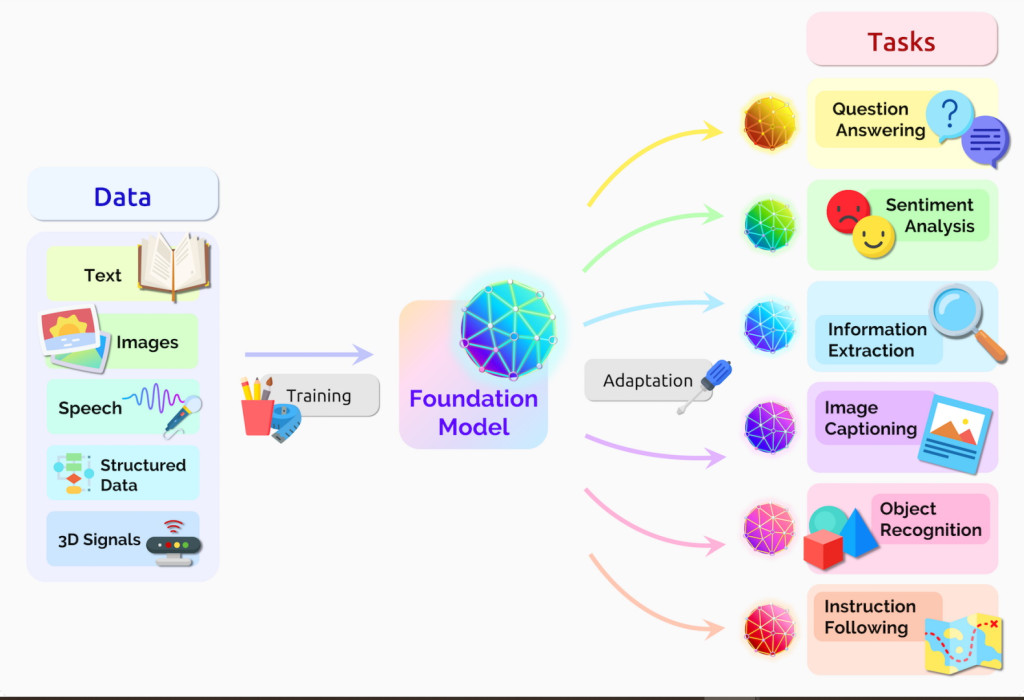
Generative AI models are a subset of machine learning that focus on training data to generate new, unseen data. They contrast with discriminative models in their capability to create new content rather than merely categorizing it.
Defining Generative AI
Generative AI is a branch of artificial intelligence where machines create new content. This includes images, text, and even sounds that did not exist before. These AI models learn from large amounts of data.
They understand patterns and details well enough to generate similar but original outputs.
This process involves neural networks, a type of machine learning algorithm inspired by the human brain’s structure and function. By training on datasets like pictures or language examples, these models can produce work akin to what they’ve learned.
Comparing Discriminative and Generative AI Models
Understanding the differences between discriminative and generative approaches is crucial when it comes understanding these models better.
Here’s a detailed comparison laid out:
| Aspect | Discriminative Models | Generative Models |
|---|---|---|
| Purpose | Classify existing data points. | Create new content based on understanding data patterns. |
| Focus | Understand the boundary between different classes in the data. | Learn the structure of data to generate similar examples. |
| Approach | Directly maps inputs to outputs. | Models how data is generated to simulate new data points. |
| Applications | Widely used in classification tasks. | Applied in computer vision, synthetic data creation, and more. |
| Examples | Logistic regression, Support Vector Machines. | Generative Adversarial Networks (GANs), Transformer-based models. |
| Challenges | Limited to classifying known categories. | Needs careful training data selection and oversight to avoid bias. |
Discriminative models are great for knowing what category something belongs to. Each has its place in machine learning, providing tools to solve different types of problems.
Types of Generative AI Models
Let’s dig deep into generative AI models and explore different types such as transformer-based models, generative adversarial networks (GANs), and diffusion models.
Here is a quick view:
| Model Type | Description | Key Features | Applications |
|---|---|---|---|
| Transformer-based Models | Models like GPT-4 and Stable Diffusion that predict what comes next by analyzing large datasets. | Self-attention mechanism for context understanding | Natural language processing, image generation |
| Generative Adversarial Networks (GANs) | Consist of two networks, a generator and a discriminator, competing to create and evaluate realistic data. | Adversarial training process | Image creation, art generation, deepfake videos |
| Diffusion Models | Models that start with random noise and iteratively refine it to create detailed and realistic images. | Gradual denoising process | Image creation, image enhancement, art generation |
Lets look at each of these models in details and understand how they work using simple examples.
Transformer-based Models
Transformer-based models, like GPT-4 and Stable Diffusion, have changed the game in natural language processing and image generation. These models learn to predict what comes next, whether it’s the next word in a sentence or the next pixel in an image.
They do this by looking at huge amounts of data, learning patterns that humans might not even notice.
By training on diverse datasets, these AI models can write essays, summarize long articles, generate art from written descriptions, and much more. Their secret lies in self-attention mechanisms that help them focus on different parts of input data to produce astonishingly accurate results.
Lets understand by using some examples.
Writing Stories
Imagine you are writing a story and you start with the sentence, “Once upon a time in a faraway land, there was a…” A transformer-based model like GPT-4 can predict the next part of your story by understanding the context and patterns in similar stories it has been trained on. It does this by looking at the words you’ve written and determining how they relate to each other. The model might continue with, “young prince who loved adventures,” because it has learned that this is a common continuation in similar tales.
Drawing Pictures
For image generation, think of describing a scene to an artist. If you say, “Draw a sunny beach with palm trees,” a model like Stable Diffusion can create an image based on your description by predicting what a sunny beach with palm trees looks like. It does this by breaking down the description into parts: “sunny,” “beach,” and “palm trees,” and understanding how these elements typically appear together. By focusing on each part of the description, the model can generate a complete and accurate image.
Generative Adversarial Networks (GANs)

Generative Adversarial Networks, or GANs, bring a twist to creating digital content. Two neural networks battle it out: one generates new data while the other decides if this data is real or fake.
Through this competition, GANs learn to produce highly realistic images, texts, and more. This method mimics an artist and a critic locked in a creative showdown. The generator improves with each round, aiming to trick the discriminator every time.
Lets understand by using some examples.
Creating Realistic Images
Imagine you want to create a lifelike image of a person who doesn’t exist. A GAN can do this by having one network (the generator) create the image and another network (the discriminator) evaluate it. The discriminator tells the generator whether the image looks real or fake. Over many rounds of this feedback loop, the generator learns how to make images that the discriminator increasingly finds real. This process is similar to an artist who keeps refining their work based on feedback from a critic until the artwork looks convincingly real.
Crafting Art
Think about generating a piece of art that resembles a famous artist’s style. The generator creates an image, and the discriminator checks if it looks like it was made by the actual artist or not. The generator learns from the discriminator’s feedback and improves its ability to create art that is indistinguishable from human-made art. This method allows GANs to craft artworks that can fool even keen observers.
This technology powers many AI applications today, from generating life-like photos to crafting art that looks like it was made by humans. Developers use tools like TensorFlow and PyTorch for building these networks on platforms provided by NVIDIA’s GPUs.
These tools help in training GANs efficiently. Each achievement of a GAN opens doors for more advanced uses in fields such as gaming graphics and deepfake videos – where realism is key.
Diffusion Models

Diffusion models, like Stable Diffusion, are a type of generative model designed to create high-quality images by transforming noisy data into clear and detailed images. These models operate by starting with a completely noisy image, which is essentially a random distribution of pixel values.
The process involves a series of iterative refinements, where the model gradually reduces the noise and adds details to the image, making it more coherent and realistic at each step.
During the training phase, the model learns to perform these refinements by being exposed to a large dataset of real images. It identifies and learns the patterns, textures, and structures present in these images.
At each step, the model predicts the noise present in the current image and subtracts it, making the image clearer. This continuous denoising process transforms the initial random noise into a detailed and realistic image.
Lets understand by using some examples.
Image Creation
Imagine you want to create a detailed and natural-looking landscape image from scratch. A diffusion model can do this by starting with random noise and gradually refining it into a coherent and realistic image. It learns how to do this by being trained on many examples of landscape images, understanding the patterns and features that make these images look real.
Image Enhancement
Think about improving the quality of a blurry photo. A diffusion model can take this low-quality image and enhance it to a higher resolution by adding fine details. This is similar to how NVIDIA’s DLSS technology works, where it reconstructs images and produces higher resolution frames by understanding and filling in the missing details.
How Generative AI Models Are Trained
Generative AI models function by training transformer-based models, implementing GAN model training and conducting diffusion model training. These processes contribute to the versatility and innovation in AI-generated media, deep learning super sampling, and code generation.
Transformer-Based Models
Training transformer-based models involves several important steps to develop effective AI models. Here’s a simplified overview of the process and we will also understand this better by using a sample task:
Model Architecture
Define the structure of the model, including the number of layers, attention heads, and feed-forward dimensions. More layers and attention heads help the model capture complex patterns, while feed-forward dimensions determine the processing power within each layer.
Training Data
Prepare large training datasets from diverse text sources, such as books, articles, and websites. Diverse data ensures the model learns a wide range of language patterns, making it robust in understanding and generating text.
Optimization Techniques
Use advanced optimization methods like adaptive learning rate schedules and regularization. These techniques help the model learn efficiently and avoid overfitting, ensuring it performs well on both training and new, unseen data.
Tokenization
Apply sophisticated tokenization methods to process and encode text inputs. Tokenization involves breaking down text into smaller units like words or subwords, converting them into numerical representations that the model can understand.
Monitoring Progress
Track the model’s learning progress using evaluation metrics such as perplexity and BLEU scores. Perplexity measures prediction accuracy, while BLEU scores assess the quality of generated text compared to human-written references.
Fine-Tuning
Adjust the model for specific tasks by incorporating task-specific goals and domain-specific data. Fine-tuning involves additional training on smaller, specialized datasets to improve the model’s performance in particular applications.
Lets understand this by a sample task:
Imagine you want to use a transformer-based model to summarize news articles. Here’s a step-by-step of how it can b done:
- Model Architecture: Choose the appropriate number of layers and attention heads for the model to handle the complexity of news text.
- Training Data: Collect a large set of news articles and their summaries to train the model on recognizing key points and summarizing effectively.
- Optimization Techniques: Apply techniques like adaptive learning rates to help the model learn efficiently and regularization to ensure it generalizes well.
- Tokenization: Break down the news articles into tokens that the model can process while maintaining the structure and meaning of the text.
- Monitoring Progress: Use metrics like ROUGE to evaluate how well the model’s summaries match up with human-written ones.
- Fine-Tuning: Adjust the model to better summarize news articles specifically, improving its ability to highlight important information and generate concise summaries.
By following these steps, the transformer-based model learns to effectively summarize text, making it a powerful tool for tasks like news summarization.
GAN Based Models
Training Generative Adversarial Networks (GANs) involves several key steps to develop effective models for generating realistic data. Here’s a simplified overview of the process:
Model Architecture
Define the architecture of the GAN, which includes two neural networks: the generator and the discriminator. The generator creates fake data, while the discriminator evaluates the authenticity of the data.
Training Data
Prepare a large dataset of real examples that the discriminator will use to learn to distinguish between real and fake data. This dataset should be diverse and representative of the domain you are targeting.
Adversarial Training
Train both networks simultaneously. The generator tries to produce data that can fool the discriminator, while the discriminator tries to correctly identify real versus fake data. This adversarial process helps both networks improve over time.
Optimization Techniques
Use optimization methods such as gradient descent and adaptive learning rates to ensure both networks learn effectively. Regularization techniques help avoid overfitting and maintain generalization performance.
Monitoring Progress
Track the performance of both the generator and discriminator through metrics like loss values and visual inspections of generated data. Adjust training parameters based on these evaluations to improve results.
Fine-Tuning
Fine-tune the GAN by adjusting hyperparameters and potentially incorporating additional data. This step helps to further enhance the quality of the generated data and ensure the model performs well on specific tasks.
Lets understand this by a sample task:
Imagine you want to use a GAN to generate realistic human faces. Here’s how it can be done:
- Model Architecture: Design the GAN with a generator to create fake faces and a discriminator to evaluate their authenticity.
- Training Data: Collect a large dataset of real human faces for the discriminator to learn what real faces look like.
- Adversarial Training: Train the generator and discriminator together. The generator produces fake faces, and the discriminator tries to distinguish them from real faces.
- Optimization Techniques: Apply gradient descent and adaptive learning rates to ensure effective learning for both networks.
- Monitoring Progress: Use loss values and visual inspections to track the quality of the generated faces. Adjust training as needed based on these evaluations.
- Fine-Tuning: Adjust hyperparameters and possibly add more data to further improve the realism of the generated faces.
By following these steps, the GAN learns to generate highly realistic human faces, making it a powerful tool for various applications like creating avatars or enhancing images.
Diffusion Based Models
Training diffusion models involves several crucial steps to develop effective models for generating high-quality images. Here’s a simplified overview of the process:
Model Architecture
Define the structure of the diffusion model, including the number of layers and the specifics of the denoising process. The architecture determines how the model refines noisy data into clear images.
Training Data
Prepare a large dataset of images that the model will use to learn how to generate realistic images. The dataset should cover a wide variety of subjects to ensure the model can handle diverse image types.
Noise Addition and Removal
During training, start with clean images and progressively add noise. The model learns to reverse this process by gradually removing the noise and recovering the original image details.
Optimization Techniques
Use advanced optimization methods such as gradient descent and adaptive learning rates. These techniques ensure the model learns efficiently and converges to a high-quality solution.
Monitoring Progress
Track the model’s performance using evaluation metrics like image quality scores (e.g., FID) and visual inspections. Adjust training parameters based on these evaluations to enhance the results.
Fine-Tuning
Fine-tune the model by adjusting hyperparameters and incorporating additional domain-specific data. This helps the model improve its performance in generating high-quality images tailored to specific applications.
Lets understand this by a sample task:
Imagine you want to use a diffusion model to generate realistic landscape images. Here’s how it can be done:
- Model Architecture: Design the diffusion model with appropriate layers and denoising steps to handle the complexity of landscape images.
- Training Data: Collect a large dataset of diverse landscape images for the model to learn various patterns and structures.
- Noise Addition and Removal: Train the model by adding noise to landscape images and teaching it to remove the noise to recover the original images.
- Optimization Techniques: Apply gradient descent and adaptive learning rates to ensure effective learning and convergence.
- Monitoring Progress: Use image quality scores and visual inspections to track the quality of generated landscape images, adjusting training as needed.
- Fine-Tuning: Adjust hyperparameters and incorporate additional landscape-specific data to further improve the realism and quality of the generated images.
By following these steps, the diffusion model learns to generate highly realistic landscape images, making it a powerful tool for various applications like art generation or image enhancement.
Generative AI Models in Action Around Us
Generative AI models are transforming various industries, creating new possibilities for innovation and creativity. Here’s how they are being used:
Generating Images with AI
Generative AI can create a wide array of images, including paintings and visual art. This technology is rapidly evolving, reshaping creativity and efficiency in image generation. Gartner predicts significant impacts on industries like product development and marketing, potentially leading to new regulations. Recent advancements include OpenAI’s DALL-E 3 and Google’s Imagen, known for creating highly detailed and realistic images from text descriptions.
Translating Text to Images
Generative AI models play a vital role in converting text into images. Models like GPT-4, DALL-E 3, and Stable Diffusion excel in understanding natural language, allowing seamless conversion of text into visual representations. This opens new opportunities for creative expression and visual content generation. Adobe’s Firefly is another recent tool enhancing capabilities for text-to-image conversion.
Converting Text to Speech
Generative AI models use advanced technology to turn text into natural-sounding speech. Tools like Google’s WaveNet and Amazon Polly transform written content into spoken language with remarkable accuracy. The latest models, like OpenAI’s Whisper and Microsoft’s Azure Neural TTS, continue to push the boundaries of naturalness and clarity in generated speech.
Crafting Audio with AI
Generative AI models create audio for applications such as speech synthesis and music composition. These models enhance music production and provide innovative tools for crafting immersive auditory experiences. Recent advancements include OpenAI’s Jukebox, which generates music in various styles, and Harmonai’s Dance Diffusion, designed for creating complex musical compositions.
Producing Videos Through AI
Generative AI enables video production using advanced neural graphics technology like NVIDIA’s DLSS, which reconstructs images and generates higher resolution frames. This technology enhances video resolution, including upscaling old movies to 4K and beyond. Applications like OpenAI’s Sora and Google’s VEO revolutionize video production, allowing high-quality videos from text prompts. Additionally, Meta’s Make-A-Video and Runway’s Gen-2 lead in AI-driven video synthesis, offering tools to generate and edit video content with ease and quality.
Partnering with a company that specializes in generative AI development services can help implement advanced AI solutions tailored to your business needs, driving both innovation and efficiency.
Popular Generative AI Models

Generative AI models are transforming various industries. Here are some of the most popular ones:
GPT-4: OpenAI’s Advanced Language Model
GPT-4, developed by OpenAI, is widely used for writing content, chatbots, and coding assistance. It excels in understanding and generating human-like text. GPT-4 has improved safety and factual accuracy compared to its predecessors, making it valuable in many fields such as content creation, customer service, and software development.
It is used by millions of users, including large organizations like Duolingo and Morgan Stanley, to enhance their services and products. Developers and businesses looking to improve text-based interactions and automate writing tasks should consider using GPT-4.
Mistral: Expert Task Manager
Mistral, developed by Mistral AI, features a Mixture of Experts (MoE) architecture that assigns tasks to the best-suited part of the model. This increases efficiency and versatility, particularly in text generation.
Mistral is recognized for its proficiency in personalized content creation and targeted advertising, making it a top generative AI model for 2024. Businesses aiming to leverage AI for specialized and efficient text generation should look into Mistral.
Google Gemini: Google’s Multimodal Model
Gemini, from Google DeepMind, combines text and images effectively. It integrates knowledge from research papers to generate and understand both written and visual content.
Gemini excels in research, education, and multimedia content creation, handling multiple types of data seamlessly. Researchers and educators who need to synthesize information from various modalities will find Gemini particularly useful.
LLaMA: Meta’s Open Source Model
LLaMA, developed by Meta AI, is an advanced open-source language model. Its open-source nature allows developers worldwide to use, modify, and improve it, fostering innovation.
LLaMA excels in understanding and generating text, supporting applications from academic research to commercial AI tools. Its accessibility makes it a powerful language generation tool for developers and researchers.
Claude 3: Conversational AI Expert
Claude 3 is designed for conversational AI, understanding and responding to dialogue naturally. It is used in chatbots, virtual assistants, and educational platforms, enhancing user interaction through context-aware responses.
Claude 3 excels in customer service, online education, and entertainment, delivering human-like responses that improve user engagement.
DALL-E 3: OpenAI’s Image Creator
DALL-E 3, by OpenAI, generates detailed and coherent images from text descriptions. This model is ideal for creating custom illustrations, advertising, and educational materials.
Its ability to produce high-quality visual content has made it popular among artists, designers, and marketers. DALL-E 3 is renowned for its creative capabilities and practical applications in generating AI art.
Stable Diffusion: Visual Innovator
Stable Diffusion, from Stability AI, creates high-quality images for concept art, graphic design, and educational visuals. It excels at turning detailed text descriptions into visually appealing images, offering new tools for digital artists and designers.
Stable Diffusion is particularly disruptive in digital art and design, making it a valuable tool for visual content creation.
Also Read:
Multimodal LLM – Disrupting the AI Game
How Does AI Image Generation Work?
Tech Behind OpenAI Sora and Stable Diffusion 3: Diffusion Transformers
Conclusion
Generative AI models offer a wide range of capabilities, including text-to-video generation, code assistance, and creating detailed images and videos. These models are developed by leading companies such as OpenAI, Google DeepMind, Meta AI, Anthropic, Stability AI, and RunwayML. Each company contributes to solving personal, professional, and creative needs in society through innovative AI solutions.
The potential use cases for generative AI span across numerous industries. In IT and software development, these models assist with coding and debugging, significantly speeding up development cycles. In marketing, they generate engaging content, from personalized ads to compelling visuals. In the medical field, they enhance imaging techniques, aiding in early diagnosis and treatment planning.
As existing generative AI models continue to evolve and new ones emerge, the future looks incredibly promising. The advancements in AI technology are poised to revolutionize not only professional fields but also everyday life, driving innovation and efficiency.
FAQs About Generative AI
1. What is generative AI?
Generative AI is a type of artificial intelligence that can create new content, like text or images, by learning from existing data.
2. How do generative AI models learn?
These models use methods like semi-supervised machine learning and neural nets to understand and generate new content. They get smarter by analyzing lots of examples.
3. Can generative AI create realistic videos or images?
Yes! Generative AI uses tools like deep fakes and text-to-image generators to make highly realistic videos and images that are hard to tell from real ones.
4. What are some examples of generative AI applications?
Examples include ChatGPT for chatting, GitHub Copilot for coding help, Midjourney for creating art, and GPT-4 for understanding natural languages better.
5. Is there a difference between the types of learning in generative AI?
Yes! There’s supervised machine learning where the model learns from labeled data; semi-supervised learning mixes labeled with unlabeled data; while unsupervised machine learning finds patterns in data all on its own.





