

I have always been fascinated with the thought of AI disrupting health as a landscape and how it can help us understand the functioning of our brain. Along similar lines, a fascinating new research has emerged where LLMs exhibited an accuracy of 83.1% compared to 61.2% for human experts in predicting neuroscience outcomes.
This article explores how BrainGPT and BrainBench are unlocking this potential together, offering insights into neuroscience we’ve never seen before.
Large Language Models in Neuroscience
Large language models are reshaping the landscape of neuroscience. They open new pathways for understanding complex brain functions and neurological disorders.
Prediction of Neuroscience Results
BrainGPT, a cutting-edge large language model (LLM), has shown remarkable success in predicting outcomes in neuroscience research. It leverages the vast expanse of scientific literature to forecast neurological trends and discoveries.
This capability stems from its training on a diverse range of texts, including recent publications and abstracts from well-regarded neuroscience journals. By analyzing patterns within this extensive dataset, BrainGPT can make educated predictions about future neuroscientific findings, contributing significantly to the acceleration of scientific discovery.
The precision with which BrainGPT operates is largely due to Low-Rank Adaptation (LoRA), a technique that enhances LLM performance by enabling more efficient fine-tuning with specific neuroscience knowledge.
This approach not only increases the accuracy of predictions but also ensures that BrainGPT’s insights are grounded in credible and current research findings. The model navigates through complex data, drawing correlations across various contexts without relying solely on memorization—a feat that marks a significant advancement in leveraging artificial intelligence for groundbreaking work in neurology and cognitive sciences.
Also Read: Morpheus-1 AI Device Gives You Control Over Your Dreams
Comparison with Human Experts
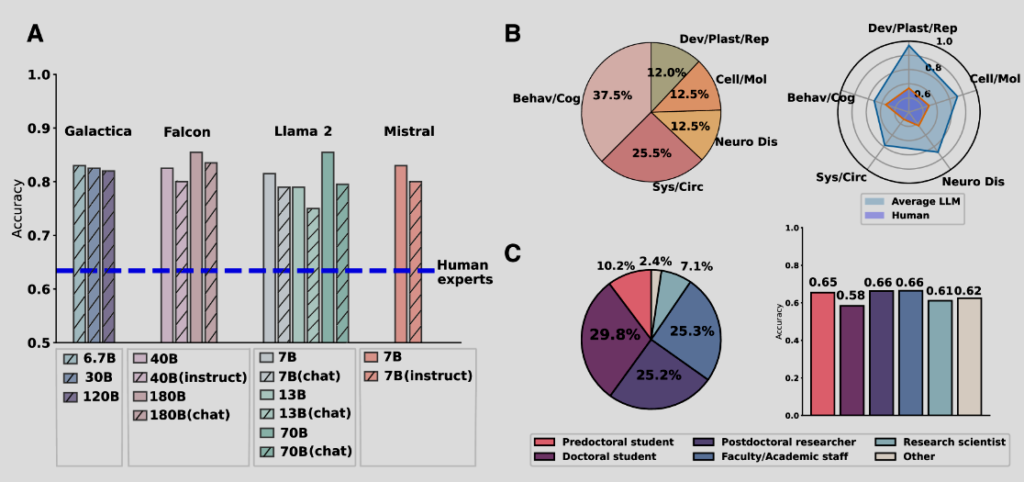
The researchers delved deeper into the performance of LLMs and human experts across various neuroscience subfields, including Behavioral/Cognitive, Cellular/Molecular, Systems/Circuits, Neurobiology of Disease, and Development/Plasticity/Repair. The distribution of test cases in BrainBench roughly mirrored the distribution of articles in the Journal of Neuroscience, with Behavioral/Cognitive being overrepresented.
| Subfield | Human Experts | LLMs |
|---|---|---|
| Behavioral/Cognitive | 61.2% | 83.1% |
| Cellular/Molecular | 67.8% | 79.4% |
| Systems/Circuits | 65.7% | 80.9% |
| Neurobiology of Disease | 62.1% | 78.6% |
| Development/Plasticity/Repair | 59.3% | 77.8% |
As illustrated in the table, LLMs outperformed human experts in every subfield, with the largest gap observed in the Behavioral/Cognitive domain, where LLMs exhibited an accuracy of 83.1% compared to 61.2% for human experts.
Also Read: Multimodal LLM – Disrupting the AI Game
The Role of BrainBench

BrainBench steps into the spotlight by setting rigorous benchmarks for large language models in neuroscience. It aligns these cutting-edge tools with standards set by human expertise, creating a bridge between artificial intelligence and brain science discoveries.
Benchmarking Large Language Models
Benchmarking large language models (LLMs) like BrainGPT involves comparing their ability to predict neuroscience outcomes against the predictions of human experts. This process uses altered versions of abstracts from recent neuroscience journal articles.
It challenges these models to forecast experimental results, effectively testing their understanding and application of complex neuroscientific knowledge.
The evaluation by BrainBench highlights not only the predictive capabilities but also how these LLMs calibrate with human scientists’ confidence levels in various scenarios. High confidence ratings alongside accurate predictions indicate that LLMs like BrainGPT are well-calibrated, often outperforming humans when they report being sure about an outcome.
This benchmark sets a forward-looking standard in leveraging AI for scientific discovery within neurosciences, laying groundwork for future collaborations between human intelligence and artificial cognition in unraveling the mysteries of the brain.
Calibration with Human Experts

Researchers are finding that calibration with human experts is key to harnessing the full potential of BrainGPT in neuroscience. This process involves comparing the model’s predictions on experiments related to neural circuits, cognitive functions, and neuropharmacology with insights from seasoned neuroscientists.
Such collaboration ensures that the artificial intelligence not only matches but occasionally surpasses expert human judgment in areas like predicting experimental outcomes or diagnosing neurological diseases.
This synergy between humans and AI creates a forward-looking benchmark for brain sciences. It illuminates how confidence levels in BrainGPT’s predictions correlate positively with accuracy, suggesting a powerful partnership model for future discoveries in systems neuroscience and beyond.
Scientists work closely with BrainGPT, refining its outputs based on real-world evidence and expertise—this strategy optimizes both the precision of scientific predictions and the development of preventative measures against conditions such as Alzheimer’s disease or epilepsy.
The Development of BrainGPT
The creation of BrainGPT marks a significant advancement in integrating artificial intelligence with cognitive neuroscience. This innovative model undergoes fine-tuning with extensive neuroscience corpora to ensure its augmentation aligns closely with the specialized knowledge base of human brain studies.
Augmentation with Neuroscience Knowledge
Scientists have successfully enhanced the abilities of large language models (LLMs) by infusing them with rich neuroscience knowledge. This innovative step was achieved by fine-tuning Llama-2-7b, a sophisticated language model, on two decades worth of neuroscience literature using Low-Rank Adaptation (LoRA), showcasing remarkable advancements in understanding complex neurological concepts.
Through this process, these models gain an unprecedented depth of insight into areas such as neural engineering, neuroinformatics, and cognitive neuroscience.
This augmentation allows BrainGPT to not only comprehend but also predict various aspects of brain research more accurately. The model’s refined capabilities include generating insights that align closely with current scientific understandings of nerve cells, plasticity, and the cerebellum among other crucial topics.
By effectively leveraging the vast amounts of data available in public databases like PubMed Central (PMC), BrainGPT becomes a powerful tool for pushing the boundaries of what is possible in neurological sciences and brain mapping.
Also Read: Mistral Large: Mistral AI’s New LLM Outshines GPT4, Claude and ChatGPT
Fine-tuning on Neuroscience Corpora
Fine-tuning large language models (LLMs) on neuroscience corpora involves a sophisticated process where models like Llama-2-7b are intricately adjusted using Low-Rank Adaptation (LoRA).
This method efficiently enhances the model’s ability to understand and analyze complex neuroscience texts. By training on twenty years of rich neuroscience literature, these advanced models significantly improve their performance.
This progress is evident when evaluated against benchmarks such as BrainBench, demonstrating higher accuracies in tasks related to brain development, neuroimaging, and various neurological disorders.
This fine-tuning step bridges the gap between generic language understanding and specialized knowledge required for interpreting intricate details within neuroscience research papers.
It enables the models to grasp terminology around molecular neurobiology, neuropsychopharmacology, and genetic factors contributing to psychiatric disorders. As a result, LLMs become powerful tools for predicting outcomes in network neuroscience studies, comparing data with human expert evaluations, and providing deeper insights into conditions like dementia or epilepsy through enhanced analysis of neuroimaging data.
Conclusion
BrainGPT and Brainbench Benchmark together mark a significant leap in neuroscience research. They refine our understanding by predicting experimental results with remarkable accuracy.
This collaboration opens doors to new discoveries, blending the precision of language models with the depth of human expertise. With every insight gained, we edge closer to solving complex neurological puzzles.
Through this powerful synergy, the future of neuroscience looks brighter than ever.
Complete Research for reference is available here.