

Google DeepMind, an artificial intelligence (AI) research division of Google, has unveiled its latest creation – Genie. This new generative model opens up exciting possibilities for content creators, game developers, researchers and more through its ability to generate interactive virtual environments and simulations.
Is this a challenger to OpenAI’s Sora? Lets find out!
What is Google Genie?
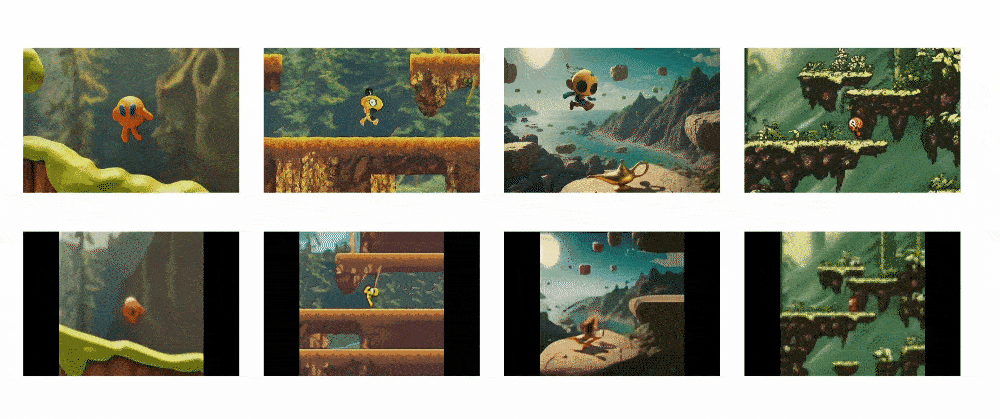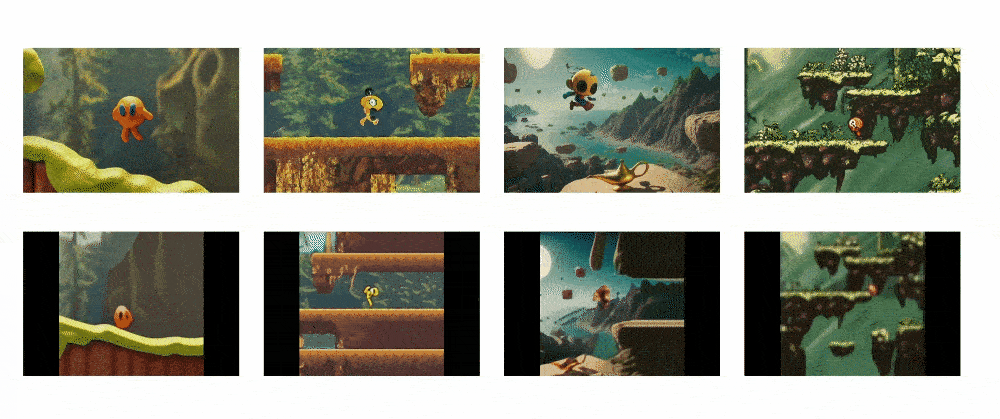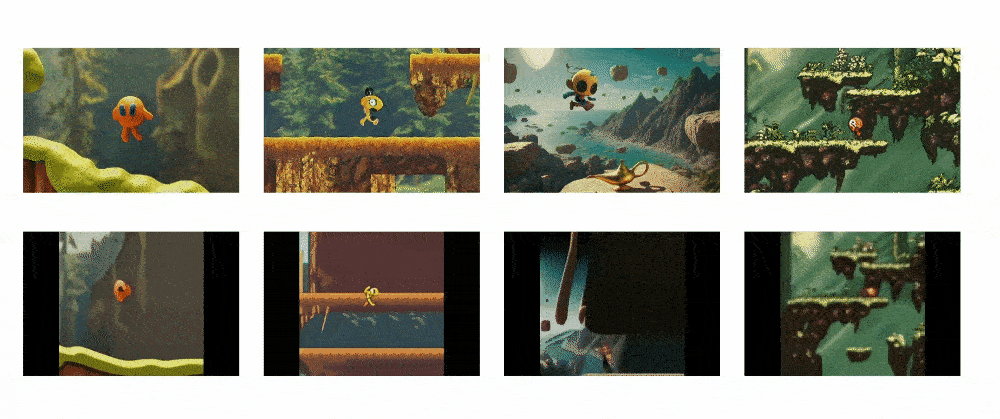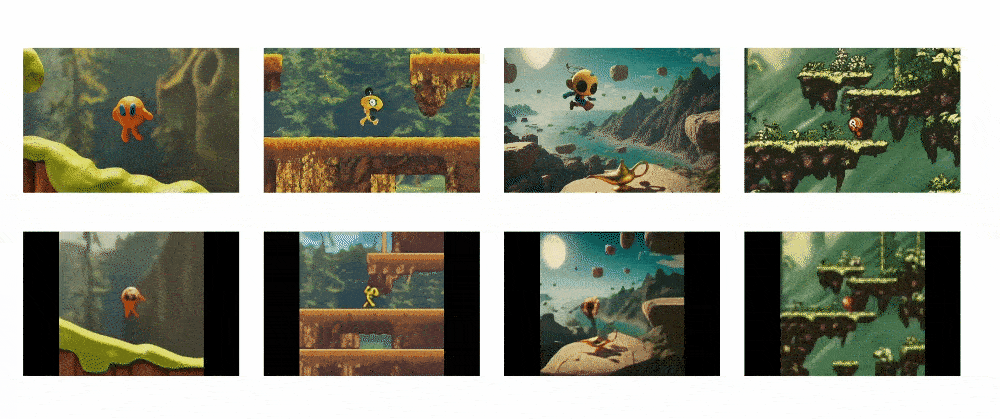
Genie is able to take a single text or visual prompt and generate an interactive and controllable environment from it that users can play with on a frame-by-frame basis.
This allows Genie to bring imagined worlds to life. Users can provide it with synthetic images, photographs, sketches or even just text descriptions, and Genie will generate a virtual world that corresponds to the prompt. Within this world, users can then control the environment and characters through actions and see the consequences play out frame-by-frame.
Key Highlights
- Generative Interactive Environments – Genie creates full 3D worlds that can be dynamically controlled at each frame rather than just generating static images or videos. This interactivity enables new applications in gaming, training simulations and more.
- Unsupervised Learning – Remarkably, Genie learns to generate these interactive environments without any labels or supervision. It is trained on a dataset of publicly available internet videos depicting 2D platform games.
- Controllable via Latent Actions – Genie infers a space of “latent actions” between frames that allow it to predict the impact of a user’s actions on the next frame. This enables smooth frame-by-frame control.
- 11 Billion Parameters – As a foundation model, Genie has an impressive 11 billion parameters. This gives it strong generative capabilities to conjure realistic environments.
- Text and Image Prompting – Users can supply an initial text description or an image such as a sketch, photograph or even another AI-generated image to kickstart Genie into generating an environment.
Read More: Google releases Google Gemma – Open Source GenAI Model
How Does Google Genie Work?

Under the hood, Genie combines three neural networks to enable the generation and control of environments frame by frame:
- A video tokenizer – Encodes raw pixel frames into discrete tokens
- A latent action model – Predicts actions between frames
- An autoregressive dynamics model – Predicts the next frame tokens based on past tokens and supplied action
The components above are arranged sequentially and allow users to start with an initial frame, supply actions frame-by-frame and have Genie predict the impact of those actions.
Remarkably, Genie is able to learn relationships between actions and environment dynamics in an entirely unsupervised manner through self-supervision on unlabeled real-world videos. The quality and realism continue to improve with more computation and data.
Video Tokenizer
The video tokenizer network converts raw pixel input frames into discrete tokens. Training this simply involves reconstructing the original frames. This is a more efficient and manipulatable representation than raw pixels.
Latent Action Model
This model is trained to predict frame transitions in the absence of any labeled actions. It does this by encoding past frames into a latent space and decoding a future frame. The key trick though is restricting the latent encoding vector into just 8 possible codes. This forces Genie to learn the most salient changes between frames – essentially a space of latent actions.
Autoregressive Dynamics Model
The dynamics model is the final component which ties everything together. It is trained to predict the token representation of the next frame based on past frames and an input latent action code. This is the model responsible for propagating the environment forward during inference based on user supplied actions.
By combining these elements together, Genie learns emergent physics and dynamics purely from unlabeled videos without human defined rewards, transitions or annotations. This is what enables the incredible flexibility and variability in the types of environments it can simulate.
Also Read: Analyzing OpenAI’s Sora – Text to Video Model
How To Access Google Genie
Google Genie is currently only available as an academic research demo while it continues to be improved and tested. Wider access is expected over the next year.
To check out Genie today, go to https://sites.google.com/view/genie-2024 where you can access the web demo and sign up for updates on future releases.
Also Read: How to use Google Imagen
Similar Tools Like Google Genie
As an emerging capability, there are not many comparable generative interactive environment models today. The most relevant alternatives are:
AI Dungeon
AI Dungeon is a text adventure game powered by OpenAI’s GPT language model. So while highly creative, it lacks graphical environments.
Unity Simulation
Unity Simulation provides a platform to generate synthetic training data by simulating virtual environments. But it lacks Genie’s flexibility – new environments still need to be manually built.
DeepMind Lab
DeepMind’s Lab platform procedurally generated simple 3D game environments from design rules for training Reinforcement Learning agents. Genie takes this further with more realistic physics and graphics.
Outside of those, Genie represents an entirely new paradigm in instantly generating boundless interactive 3D experiences from minimal user prompting. We are truly just scratching the surface of what will be possible in years to come as generative models grow ever larger and more capable.
Conclusion
While Google DeepMind views the current Genie model as an “initial proof of concept,” they believe this approach could unlock significant future capabilities.
Compared to existing video prediction models, Genie is unique in its controllability through a learned latent action space, allowing users to actively “play” the model. It also stands out in its ability to generate entirely new playable environments simply from a single image prompt. The researchers suggest Genie could be scaled up with even more internet video data to simulate extremely diverse environments.
Most promising direction for these kind of model, including the OpenAI, Sora, is to train generalist reinforcement learning agents. Since new environments can be created endlessly from Genie, it provides an unlimited source of data for developing adaptable agents, potentially leading to more broadly intelligent AI systems.
Frequently Asked Questions
How good is the quality of environments produced by Genie today?
Genie is best for 2D game-like environments currently, producing somewhat simplistic scenes compared to modern 3D rendered games. But it shows exceptional promise by generating worlds holistically rather than piecing assets together. Expect quality improvements over time.
Does Genie work for complex real-world scene generation?
Not yet – it has only been demonstrated for simplistic 2D game environments so far. The dynamics model would need to be adapted and trained on far more heterogeneous data showing the full complexity of the real world across scenes, textures, lighting and more.
