Synthetic data is made by computer programs instead of collected from real life. It looks and acts like real data without using personal details. By 2030, synthetic data will be a big part of AI projects, says Gartner.
There are different types. Partial synthetic data replaces some parts with fake ones. Full synthetic data uses all fake info but still keeps patterns from real-world sets.
How do we make it? We use tools like Generative Adversarial Networks (GANs) or Variational Auto-Encoders (VAEs). These models learn from real examples to create new, similar examples.
Why use this fake stuff?
It helps train and test AI while keeping privacy intact. For example, it’s used in healthcare and finance where privacy rules are strict.
Making synthetic data has many benefits – more endless amounts of information can be generated which helps fight bias and keep things fair. But there are hurdles too. Quality checks must ensure it’s accurate; plus, people sometimes misunderstand its reliability.
Exciting new methods include GANs improving how we create realistic samples for training machine learning systems!
Key Aspects of Synthetic Data
- Synthetic data, created by Generative AI models, provides safe and privacy-protected data for training and testing AI models.
- There are two main types: partial synthetic data replaces parts of real data, while full synthetic data mimics the statistical properties but doesn’t use any original pieces.
- By 2024, synthetic data will account for 60% of all AI project data according to Gartner; it helps reduce bias and ensures compliance with privacy regulations like GDPR.
- Advanced techniques such as Generative Adversarial Networks (GANs) and Variational Autoencoders (VAEs) create high-quality synthetic datasets that improve AI model accuracy without compromising user privacy.
- Tools like Datomize, MOSTLY.AI, Synthesized, Gretel, CVEDIA, Rendered.AI, and transformer-based models like GPT play crucial roles in generating realistic synthetic data across various industries including healthcare and finance.
What is Synthetic Data?
Synthetic data comes from Generative AI models trained on real-world samples. These models create new data that looks like the original but doesn’t contain personal information. This makes synthetic data safe and fully anonymous, preventing re-identification risks.
By 2030, most of the data used in AI and analytics projects will be synthetically generated. Gartner predicts that by 2024, synthetic data will account for 60% of all AI project data.
Data scientists use this type of data to train and test their neural networks without worrying about privacy issues.
Types of Synthetic Data
There are different kinds of synthetic data. Some are only partly artificial, while others are entirely made up.
Partial Synthetic Data
Partial synthetic data replaces part of real data. It helps with making decisions while keeping privacy intact. Partial synthetic data can be useful in training AI models, doing analytics, testing software, and creating demos.
It reduces the risk of re-identification and high feature correlations. This type of data also offers a contrast to biased information, which helps reduce bias during AI training.
Full Synthetic Data
Full synthetic data is completely new data created from scratch. It mimics the statistical properties of real-world data. This type of data keeps the same relationships and structures as the original dataset without using any actual pieces of it.
In industries like offshore software development, medical research, and performance testing, full synthetic data ensures high machine learning performance while respecting privacy rules.
It solves many issues related to privacy and regulations, reducing costs and speeding up processes. You can store this data locally instead of needing access to central servers. Full synthetic datasets allow unlimited generation possibilities for better AI-powered systems.
Data is a precious thing and will last longer than the systems themselves. – Tim Berners-Lee
How Synthetic Data is Generated

Synthetic data can be made using different techniques like statistical distribution and deep learning. These methods help create realistic data, which is useful for training AI models.
Statistical Distribution Methods
Statistical distribution methods generate synthetic data by mimicking the patterns found in real data. These methods involve creating distributions based on actual data attributes, such as age ranges or income levels, to produce realistic yet anonymized datasets.
In healthcare and finance, statistical models ensure sensitive information is protected while retaining key insights.
Chi-square tests can help assess how well the synthetic data matches original data distributions. By using these techniques, you ensure your AI model gets accurate input without risking privacy issues.
This process supports fields like legal work where confidentiality matters most – enabling safer collaboration with meaningful copies of real datasets.
Model-Based Techniques
Model-based techniques use deep learning models to make synthetic data. These methods create data based on other models and patterns. Tools like transformer-based models, such as GPT, work well for natural language processing (NLP).
These models can generate text that feels natural and realistic.
AI modeling relies heavily on quality data, says Andrew Ng, an AI expert.
In computer vision, model-based techniques produce high-accuracy images with labels for training AI. They are used in banking, healthcare, automotive, robotics, advertising – making them versatile and essential tools in artificial intelligence development.
Deep Learning Methods
Deep Learning Methods create new data with advanced neural networks. Generative Adversarial Networks (GANs) use two networks called the generator and discriminator. The generator creates data, while the discriminator checks its quality.
This method helps improve data accuracy over time.
Variational Auto-Encoders (VAEs) use an encoder-decoder setup. They compress real data into a simpler form and then rebuild it as new synthetic data. VAEs can generate high-quality samples by learning from compressed representations of original datasets.
Both GANs and VAEs are key tools in synthetic data generation, used widely by companies like Datomize and MOSTLY.AI for tasks in artificial intelligence modeling, including training AI models accurately.
Main Uses of Synthetic Data in AI

Synthetic data helps to train and test AI models.
Training AI Models
AI models need lots of data to learn. Synthetic data provides this extra training material. A 2016 paper showed no significant difference between AI models trained on synthetic versus real data.
Using synthetic data also helps reduce bias during training.
Companies in healthcare, finance, and legal fields use synthetic data for privacy protection. Synthetic data ensures sensitive information stays safe while allowing AI models to train effectively.
This method offers a way around the problem of limited real-world examples without compromising privacy or quality.
Testing AI Algorithms
Synthetic data helps test AI algorithms in a controlled way. Self-driving cars, autonomous vehicles, drones, and robots rely on such tests. These virtual worlds provide safe settings to refine actions without risk.
Amazon Web Services (AWS) uses synthetic data tools for testing algorithms. They create copies of sensitive information for sharing and collaboration without privacy concerns. This process ensures high-quality results while protecting user privacy.
Benefits of Using Synthetic Data

Synthetic data offers many perks like endless data creation, keeping personal info safe, and cutting down on unfairness.
Unlimited Data Generation
Creating synthetic data allows for endless possibilities. By using statistical distribution methods and deep learning techniques, we can generate vast amounts of new data. This is crucial because it fills the gaps in real datasets and updates old information.
For instance, companies like Mostly AI create realistic customer behavior datasets to train and test AI models.
The ability to make unlimited data helps improve artificial intelligence quality significantly. It creates rich versions of original data while ensuring privacy protection. More importantly, this process prevents biases from creeping into AI models by offering diverse examples not found in real-world samples.
Privacy Protection
Synthetic data generation is safe and fully anonymous. It prevents re-identification, ensuring privacy protection for users. Unlike legacy data anonymization techniques that risk privacy and degrade utility, synthetic data offers a reliable alternative.
For instance, it helps overcome challenges posed by regulations like GDPR.
AI models trained with synthetic data can replace original datasets while safeguarding personal information. This approach makes sharing data safer and more effective for development.
By creating detailed yet anonymous records, synthetic methods allow businesses to innovate without compromising user confidentiality or violating laws.
Bias Reduction
Bias in AI models can lead to unfair decisions and outcomes. Synthetic data helps reduce bias by offering balanced datasets. This approach corrects skewed information. For example, if an AI model shows gender bias, synthetic data can introduce diverse samples to counteract this issue.
Using synthetic data also aligns with privacy regulations. Traditional methods may require central server access, risking personal information exposure. Local storage of synthetic data ensures compliance while improving fairness in training AI models through diverse and unbiased statistical distributions.
Challenges in Synthetic Data Generation
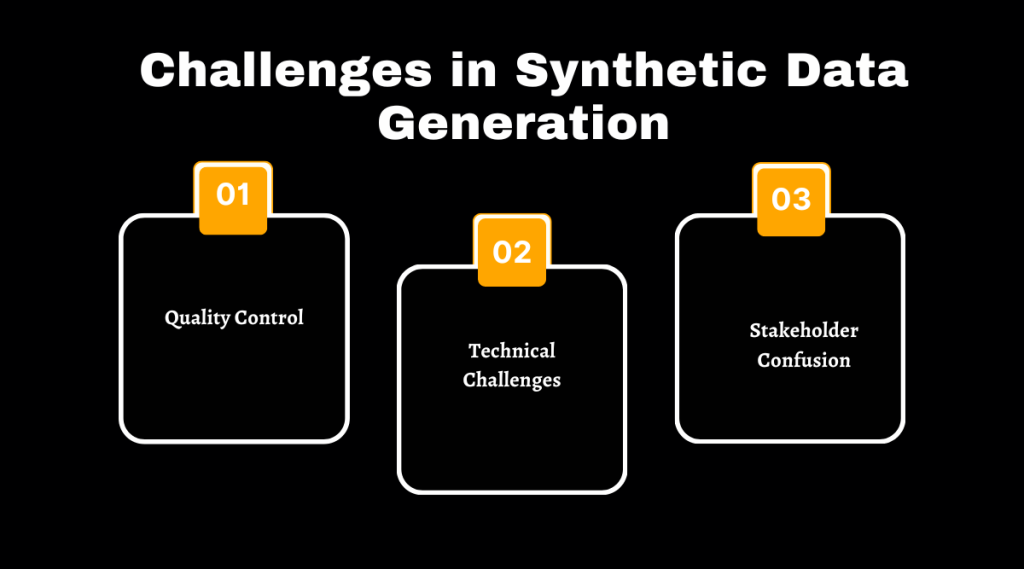
Creating synthetic data can be tough. Ensuring the quality stays high is a big challenge.
Quality Control
Quality control in synthetic data generation is essential to ensure data quality. Automated QA processes check the accuracy and fidelity of synthetic data to match original datasets.
This step helps detect and fix errors quickly. There are limitations, like difficulty replicating outliers and ensuring reliability.
Ensuring diversity and realism in synthetic data requires controlling random processes precisely. To achieve high-quality results, techniques include statistical distribution methods, model-based techniques, and deep learning methods.
These approaches help maintain balance across different types of generated data while reducing biases – critical for training accurate AI models effectively.
Technical Challenges
Creating high-quality synthetic data is tough. Ensuring that the generated data matches the real-world scenarios can be tricky. It often requires advanced AI knowledge and specialized skills – like those used in building Generative Adversarial Networks (GANs) or Variational Auto-Encoders (VAEs).
These technologies need experts who understand deep neural networks well.
Another challenge is maintaining quality control. The synthetic data must be accurate and useful for training machine learning models without introducing errors or biases. This task demands rigorous testing and validation, which can consume many resources and time.
Stakeholder Confusion
Stakeholders often get confused about synthetic data. Some question its reliability and use. Concerns about data privacy, ownership, and misinformation add to the confusion. Synthetic data should be embraced for responsible and beneficial use.
Quality control issues make it hard to trust the generated data samples. Technical challenges complicate this further. Plus, some people worry that using synthetic data might spread false information or cause bias in AI models without proper testing protocols like those used by Amazon Web Services or NVIDIA Drive.
Latest Innovations in Synthetic Data Generation
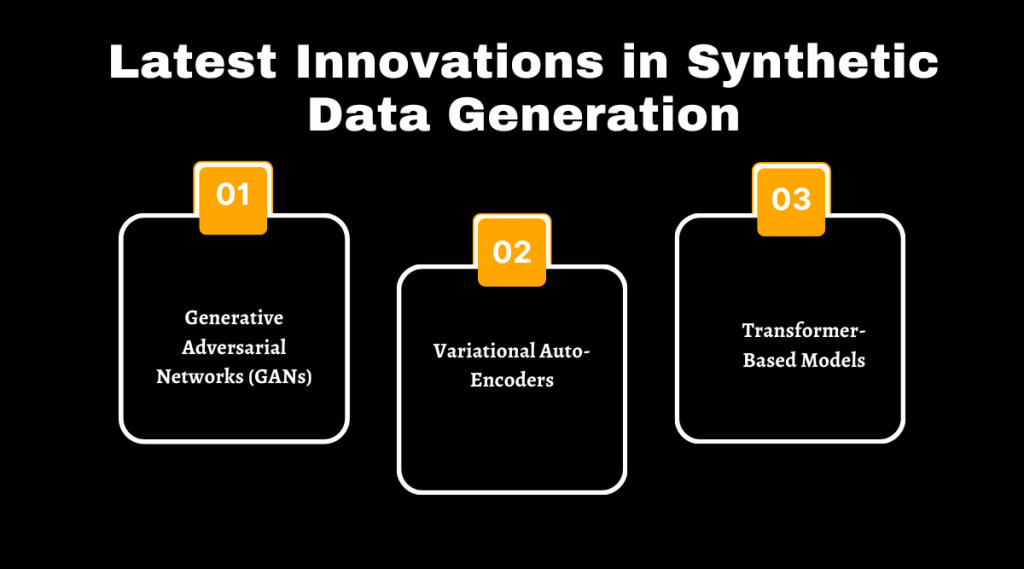
Generative Adversarial Networks (GANs) and Variational Autoencoders are making waves in synthetic data generation. Transformer-Based Models add even more power, changing the game for creating realistic data.
Generative Adversarial Networks (GANs)
GANs have two key parts: a generator and a discriminator. The generator creates new data, while the discriminator checks if this data is real or fake. This game between the two helps improve the quality of synthetic data over time.
GANs are powerful tools for generating synthetic data in AI.
Tools like Datomize, MOSTLY.AI, and Synthesized use GANs to safely create copies of sensitive information. These generated datasets allow safe sharing without risking privacy issues.
Thanks to their efficiency, GANs help reduce biases in training AI models by supplying diverse examples for better learning outcomes.
Variational Auto-Encoders
Variational Auto-Encoders (VAEs) use an encoder-decoder setup to create new data from compressed representations. VAEs work by encoding input data into a smaller, simpler form, then decoding it back into its original or a new format.
This process helps generate synthetic data on demand and pre-labels it for machine learning tasks. Tools like Gretel, CVEDIA, and Rendered.AI employ VAEs for this purpose.
These advanced techniques support AI model training and testing in various fields – data-science projects benefit significantly from their applications. The architecture ensures accurate synthetic data generation while keeping privacy intact.
Uses include creating digital twins or simulating scenarios where real-world data is hard to obtain.
Transformer-Based Models
Transformer-based models like GPT excel in natural language processing. They generate synthetic data used by many industries, including banking and healthcare. These models create accurate images with labels for AI training – take the DALL-E project by Microsoft, which generates over 2 million pictures daily.
These models also improve explainable AI by producing clear, detailed outputs that help understand complex algorithms. Synthetic data creation leverages these models to train and test various AI systems without risking sensitive information.
In summary: accurate, efficient, secure.
Conclusion
Synthetic data is vital for AI modeling. It helps generate limitless training data and protects privacy. This data reduces biases in models. Key tools like GANs and Auto-Encoders push this field forward rapidly.
By 2030, most AI projects will use synthetic data as predicted by Gartner.